CoFiF
The first large Corpus of Financial Reports in French Language
Corpus for Finance
CoFiF is the first large corpus comprising company reports in the French language. It contains over 188 million tokens in 2655 reports, covering four types of documents:
- Reference documents (documents de référence) published annually, usually in the months following the end of the calendar year, and contain information regarding the financial situation and perspectives of a company
- Annual reports (résultats annuels) which summarises a company’s business and activities throughout the previous year
- Semestrial reports (résultats semestriels): similar to annual reports in content but published every 6 months
- Trimestrial reports (résultats trimestriels): similar to annual reports but published every 3 months
These documents are collected from the 60 largest French companies listed in France’s main stock indices CAC40 and CAC Next 20. The corpus spans over 20 years, ranging from 1995 to 2018.
CoFiF structure
In addition to the PDF files which were collected from enterprises (all rights reserved), we provide the reports in raw text without further pre-processing. The following image illustrates CoFiF corpus directories where file and folder names may contain metadata such as date of publication (year), type of document (DR: reference document, A: annual, S: semestrial, Q or T: trimestrial):
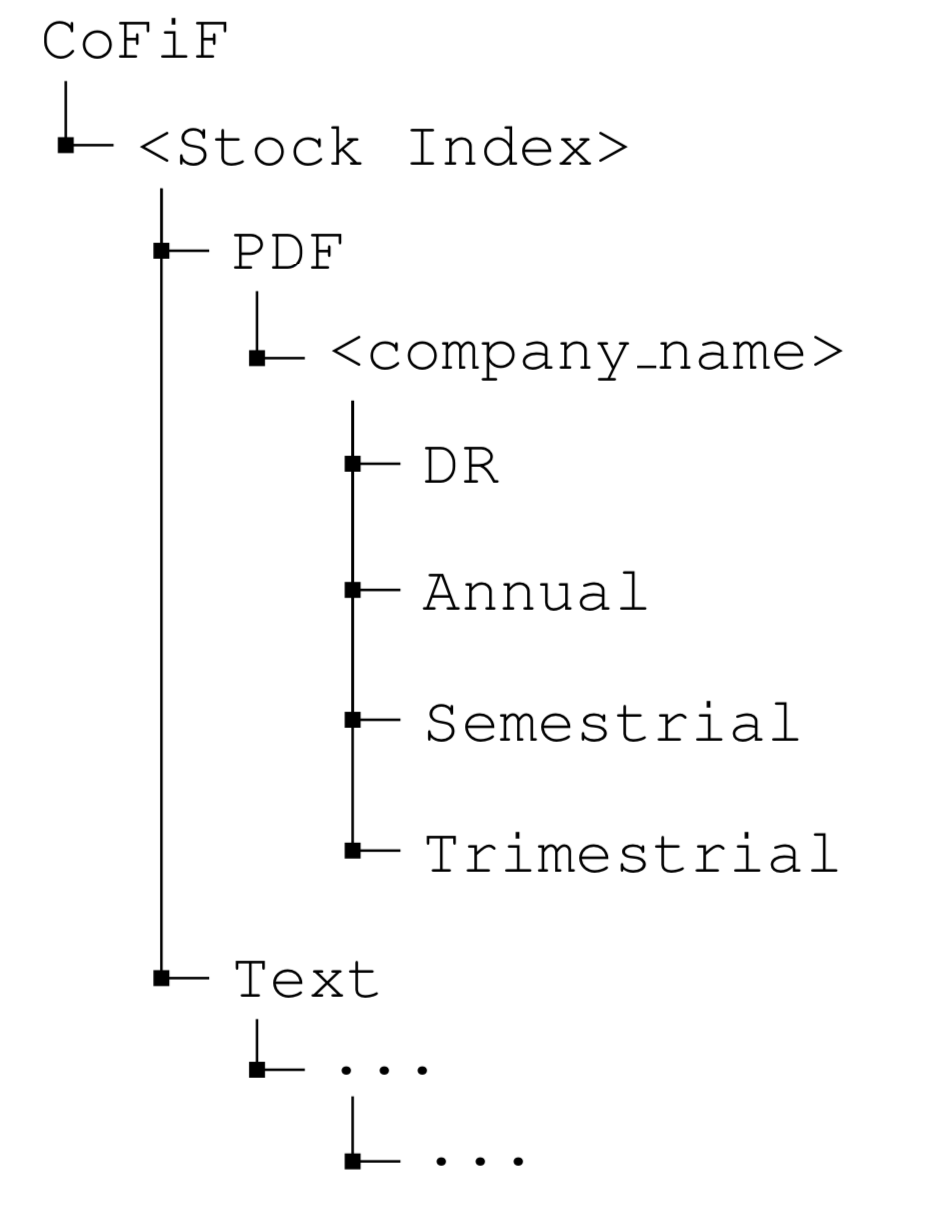
In addition to the PDF files and the raw text, we also provide a cleaned dataset CoFiF_cleaned_all.txt which was used for training our language model reported in the paper.
Get CoFiF
CoFiF can be downloaded at https://github.com/CoFiF/Corpus. The PDF files of the corpus can be found here.
Reference
If you’re using CoFiF in your researches, please don’t forget to cite this paper:
@inproceedings{daudert-ahmadi-2019-cofif,
title = "{C}o{F}i{F}: A Corpus of Financial Reports in {F}rench Language",
author = "Daudert, Tobias and
Ahmadi, Sina",
booktitle = "Proceedings of the First Workshop on Financial Technology and Natural Language Processing",
month = "12 " # aug,
year = "2019",
address = "Macao, China",
url = "https://www.aclweb.org/anthology/W19-5504",
pages = "21--26",
}
License
This corpus is openly available for non-commercial use under the Attribution-NonCommercial-ShareAlike 4.0 International.
Contact
If you have any questions or suggestions, you can contact Sina Ahmadi (sina.ahmadi at insight-centre.org) and Tobias Daudert (tobias.daudert at insight-centre.org).